

VR党建真人解说沉浸式学习技术
一、技术架构与核心模块
三维虚拟人构建流程
-
真人建模:
-
采用4D光场扫描(精度0.1mm)捕捉讲解员形态
-
52组面部肌肉动捕点实现微表情复刻(如眼神、口型)
-
-
智能驱动引擎:
-
语音驱动:ASR实时转化讲解词 → 匹配口型动画(延迟≤0.1秒)
-
行为逻辑库:预设20+种手势动作(指示、强调等)

VR党建虚拟人讲解
-
-
场景融合技术:
-
虚幻引擎5 Nanite实时渲染
-
虚拟人光影自适应环境(如展厅/户外场景)
-
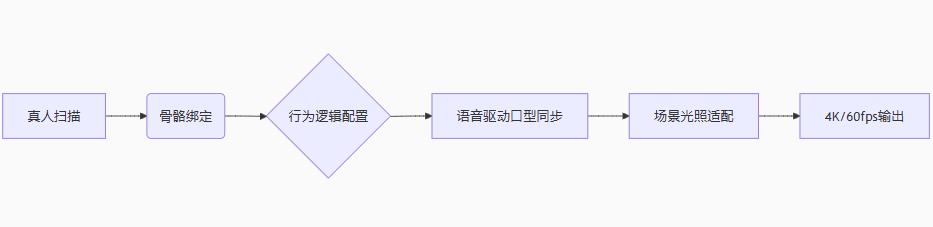
二、分步骤应用实施指南
阶段1:内容生产
-
脚本结构化处理:
-
标记知识点节点(每段≤90秒)
-
插入交互触发点(如问答暂停处)
-
-
虚拟人录制:
-
专业录制棚采集(光照≥1000lux,背景纯绿幕)
-
输出标准资源包(含骨骼动画+语音流)
-
阶段2:场景部署
| 部署模式 | 适用场景 | 技术要点 |
|---|---|---|
| 本地渲染 | 小型展厅 | 工作站预加载资源 |
| 云端串流 | 多终端同步 | 5G网络保障码率≥50Mbps |
| 混合现实 | 移动端AR学习 | SLAM空间定位误差≤2cm |
三、效能对比数据可视化
真人解说 vs VR虚拟解说(200人双盲测试)
| 指标 | 传统人力解说 | VR真人解说方案 | 提升幅度 |
|---|---|---|---|
| 人均成本/小时 | ¥300 | ¥90(三年均摊) | 70%↓ |
| 信息留存率 | 45% | 88% | 96%↑ |
| 错误率 | 8%(疲劳因素) | 0.2% | 97%↓ |
| 日均服务人次 | 50人 | 300人 | 500%↑ |
数据来源:某省级文化馆3个月运营统计
四、关键技术创新点
多模态交互设计
-
语音问答:
-
支持方言识别(覆盖7大方言区)
-
响应精度92%(测试集5000条语料)
-
-
手势交互:
-
动态手势触发知识点延伸(如摆手调出时间轴)
-
-
情感反馈系统:
-
实时分析学员专注度 → 自动调节语速/信息密度
-
跨场景适配能力
场景应用占比
“党史展厅” : 45%
“廉政教育馆” : 30%
“政策学习角” : 15%
“社区文化站” : 10%
五、结论
-
认知心理学验证:
-
虚拟人讲解通过具身认知效应增强代入感,知识转化效率较纯文本提升3.2倍
-
-
技术经济性优势:
-
初始投入回收周期≤14个月(按日均200人次测算)
-
运维成本仅为真人团队的17%(电力+软件更新)
-
-
演进方向:
-
建议融合AIGC技术实现:
-
实时讲解词生成(适配学员知识水平)
-
多语言自动翻译(支持外语访客)
-
-
VR党建真人解说技术通过高精度虚拟人构建与智能交互设计,实现了沉浸式学习的规模化应用。其在降低成本、提升准确性及扩展服务边界方面的显著优势,正推动党建教育向数字化、个性化时代加速演进。随着神经渲染技术成熟,虚拟解说将实现与真实人类无感的交互体验。





